今回は、HADでデータを操作する方法について説明します。
今回の説明ポイントは、
- 欠損値の処理
- フィルター機能(分析に使用するサブジェクトの選択)
- 変数の統制(偏相関分析)
- 変数の合成
- 変数の変換
の5つです。
具体的には、続きを参照してください。
◆欠損値の処理
HADではデフォルトではピリオド"."が欠損値記号です。しかし、RのデータではNAが欠損値記号だったりして、欠損値記号を他に変えたい場合もあると思います。そこで、HADの欠損値記号の変更方法を説明します。
まず、モデリングシートの「HADの設定」ボタンを押します。すると、以下のようなユーザーフォームが立ち上がります。
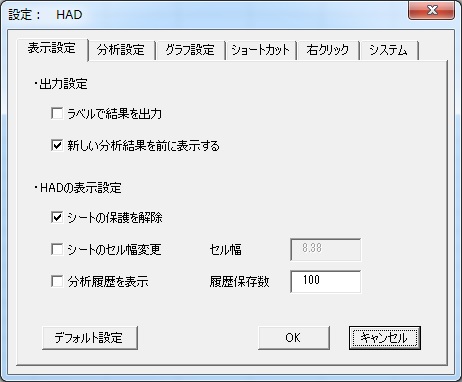
ここで、「分析設定」タブを選ぶと以下のように欠損値についての設定が変更できます。
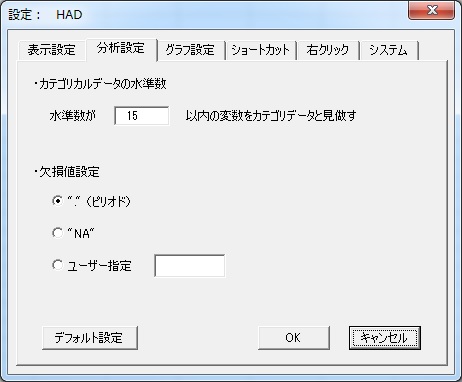
デフォルトのピリオドから、NAやほかの記号や数値を選択できます。もしNAに変更した場合、データにピリオドがあるとエラーを返すので注意してください。HAD内では欠損値は一つだけ設定可能です。ただし、空白を欠損値にすることはできません。
次に、データ分析においてどのように欠損値処理をするかについて説明します。要約統計量やデータの変換は、各変数ごとに欠損値を省いて処理します。また、相関分析(順位相関、マルチレベル相関、ペアワイズ相関、共分散行列など)などの2変数間の関連を見る分析は、デフォルトではペアワイズ削除が用いられます。それ以外の、回帰分析、t検定、分散分析、因子分析ではリストワイズ削除を行います。
ペアワイズ削除とは、2変数の組み合わせで少なくとも片方が欠損していれば削除する、というものです。リストワイズ削除とは、使用変数に入力したすべての変数で少なくとも一つ欠損していればオブジェクトを削除する、というものです。したがって、回帰分析や因子分析をする場合は、使わない変数は使用変数には投入しない方がデータ数は多くなります。
また,構造方程式モデルを使えば,欠損データを完全情報最尤法で推定することもできます。
◆フィルタ機能
フィルタとは、分析に使わないサブジェクトを前もって省いておく機能です。例えば、男性と女性を別々に分析したい場合は、女性を分析上で省くことができると便利です。
HADではフィルタ機能で分析に使わないサブジェクトを指定することができます。
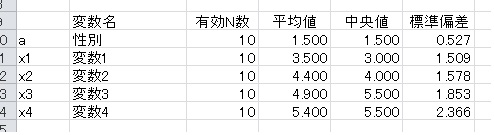
以下のように、モデリングシートの下の方にある「フィルタ」の列に得点をいれると、「その得点を持ったサブジェクトを分析で除外」することができます。
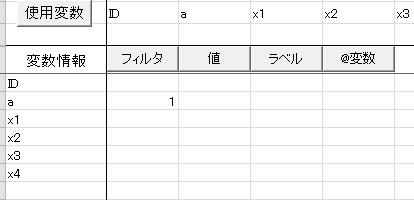
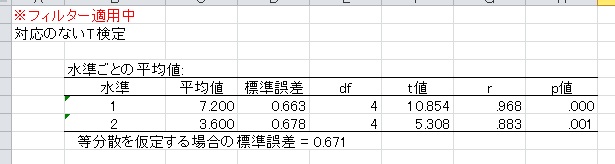
上の図の例の場合、変数aが"1"のサブジェクトを分析から省きます。変数aは1と2が半分ずつの変数なので、サブジェクトの半分をこの操作で省くことになります。
また、"<1"と入力すると変数が1未満のサブジェクトを省きます。同様に">1"とすると1より大きいサブジェクトを省きます。さらに、"*1"とすると、変数が1以外のサブジェクトを省きます(つまり、1であるサブジェクトだけを分析に使います)。
フィルターがうまく機能しているかどうかは、「起動」ボタンを押して「欠損値処理後のデータを出力」を選択してOKを押すと、フィルター機能によってデータが欠損値扱いになっているので、確認することできます。
例えば、変数aのフィルターに1を入力した場合、次のようなデータが分析されていることがわかります。
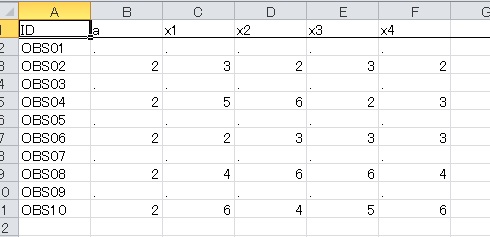
変数aが1のデータがすべて削除され、2のデータだけが残っています。
フィルタはGUI(グラフィカルユーザーインターフェイス)を使って編集することもできます。変数情報のところにある「フィルタ」ボタンをクリックすると、以下のようなユーザーフォームが立ち上がります。

変数名、値を指定して、除外の条件を選択すればフィルタの設定が完了です。もしフィルタ設定が煩雑になった場合、現在のフィルタ設定を変数化すると便利です。フィルタ変数の作成ボタンを押すと、現在のフィルタ設定を0と1でコードした変数を作成します。1が除外、0が分析に使用を意味しています。このフィルタ変数の1を除外すれば、複雑なフィルタの設定も簡単に実行できます。
フィルタを設定すると、分析結果のシートの一番上に、「フィルター適用中」と表示されます。
◆値ラベルの設定
HADは数値データしか読み込みませんが、各数値にラベルを設定することができます。
例えば、男性が1、女性が2というようにコードされていた場合、1が男性と表示されるようにすることができます。変数情報のところにある、「値」ボタンをクリックすると、以下のようなユーザーフォームが立ち上がります。
このフォームに、値とラベルをそれぞれ入力すると・・・
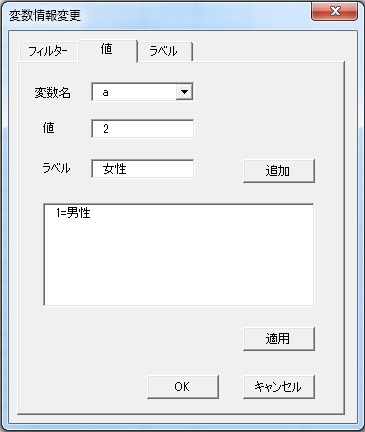
以下のように、値のところに「1=男性, 2=女性」というように入力されます。

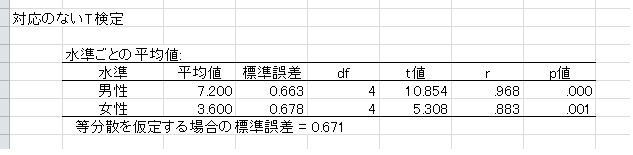
GUIを使わなくても、自分でセルに直接入力しても大丈夫です。その場合、数字とイコール、カンマは半角で入力する必要があります。値ラベルを設定した状態でt検定を行うと、以下のようにラベルで結果が表示されます。
◆変数ラベルの設定
尺度のように、変数名とは別に尺度項目をラベルにしたい場合もあると思います。変数のラベルは変数情報の「ラベル」のところに入力します。GUIでも入力可能ですが、直接セルにコピーアンドペーストするほうが楽かもしれません。
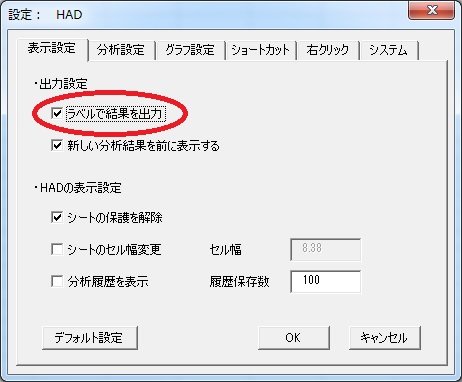
変数ラベルを分析結果に反映させたい場合は、「HADの設定」をクリック→「表示設定」→「ラベルで結果を表示」にチェックします。
ラベルを設定した状態で、分析をすると、たとえば以下のように表示されます。
◆変数の統制(偏相関分析など)
HADでは、分析の際に特定の変数でコントロールした結果を出力することができます。(一部の分析には非対応です)
まず、モデリングシートで使用変数を指定するときに、統制変数を$の後に書くことで変数の統制が可能です。
以下のように書きます。
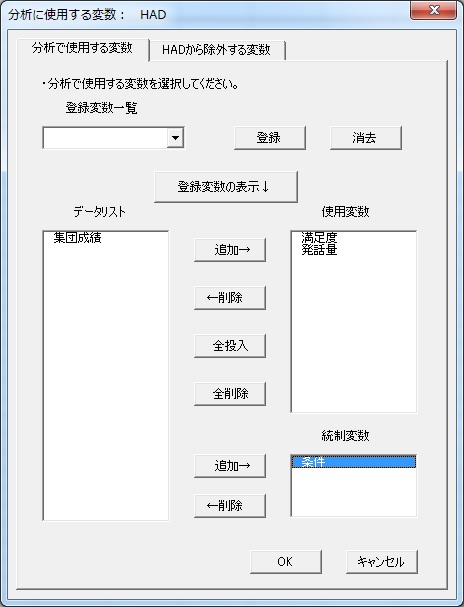
この例では、満足度と発話量が分析に使用する変数、条件が統制変数です。統制変数は、統制変数名がセルを選択した状態で、モデリングシートにある「統制変数を投入」ボタンを押せば、使用変数の後に自動的に入力されます。あるいは、GUIで設定することもできます。使用変数に満足度と発話量、統制変数に条件を指定して、OKを押すと、上と同じように入力されます。
この状態で、相関分析をしてみましょう。「分析」ボタンを押して、「相関分析」をチェックしてOKボタンを押します。すると、以下のような結果が得られます。
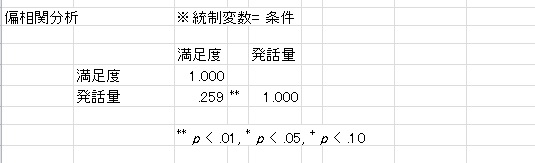
このように、条件で統制した相関係数が計算されます。
統制変数は、複数指定することもできます。$のあとに指定した変数すべてが統制変数として扱われます。また、統制変数で回帰した残差得点を出力することもできます。「データセット」ボタンを押して、データセットの出力タブにある「選択した変数を出力する」にチェックして、Okを押します。すると、統制変数によって回帰した時の残差得点が出力されます。
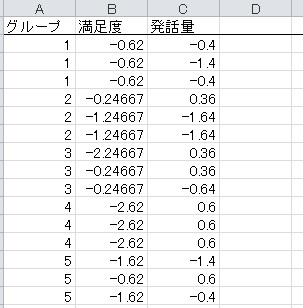
なお、統制した分析はこの残差得点を利用して行っているので、すべての変数の平均は0になります。要約統計量で平均値を算出してもらえると、それが確認できます。
統制変数を利用した分析が可能なのは、相関分析、回帰分析、媒介分析、因子分析です。これらの分析は、偏相関行列を用いて分析を行います。分散分析や順位相関などのカテゴリカルな分析では利用できないので注意してください。
◆変数の合成
心理尺度などを合成して、尺度得点を計算したいことがあると思います。HADでは以下の2通りの方法で変数を合成できます。
- 「変数の作成」ボタンから、変数を合成する
- 因子分析を使って、因子得点を計算する
2.については因子分析のところで詳しく説明する予定なので、今回は1.について説明します。
変数の作成ボタンを押すと、以下のようなユーザーフォームが立ち上がります。

4つの選択肢をどれか一つチェックしてOKボタンを押すと、変数の合成得点が算出されます。
- 使用変数を平均する:使用変数に入力した変数の平均値を計算します。
- 使用変数を合計する:使用変数に入力した変数の合計値を計算します。
- 使用変数の主成分得点を使用する:使用変数に入力した変数の第一主成分得点を計算します。
- 最初の変数から残りの変数を引く:変数の差得点を計算するのに用います。
これらの操作は、データを標準化した得点を対象にすることもできます。
◆変数の変換
連続的な変数を、高群・低群のように2群に分けたい場合、変数を2値化する必要があります。HADでは、上の変数の合成と同様に、「変数の作成」ボタンを押すことで変数の2値化が可能です。変数の作成ボタンを押して、「ダミー変数」タブを押すと、以下のような画面になります。

2値化は、平均値か中央値を基準値にして、基準値より大きい値を1、小さい値を0に変換したデータを出力します。また、基準値と同じ値を持つサブジェクトがいた場合、そのサブジェクトを高群にするか低群にするか、あるいは欠損にするかを選ぶことができます。中央値を基準値にする場合は特に注意が必要です。
次に、データを標準化したり、中心化したりしたい場合の方法です。標準化は、平均を0、標準偏差を1になるようにデータを変換することです。中心化は平均だけを0にする変換です。変数の作成ボタンを押して、「尺度変換」のタブを開きます。
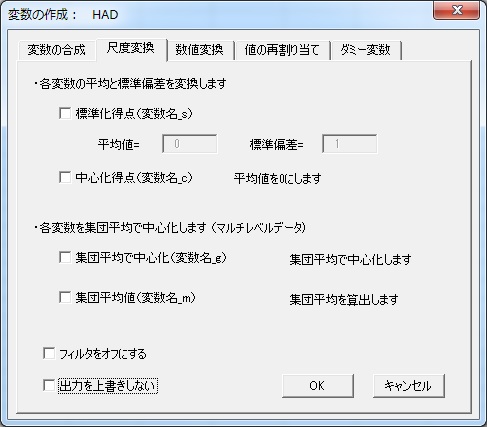
「標準化得点」と「中心化得点」をそれぞれ選択して、OKを押せば標準化得点と中心化得点が出力されます。標準化得点は_s、中心化得点は_cが変数名の後につきます。
また、もしマルチレベルデータの場合は「マルチレベルデータ」をチェックすると、「グループ平均センタリング」と「グループ内平均」が選択できるようになります。グループ平均センタリングは、各集団の平均値を得点から引いた値を出力します。グループ内平均は、その各集団の平均値を各サブジェクトの得点として出力します。
◆値の再割り当て
尺度得点の1点から3点を1、4点から5点を2、というように、変数の値を別の値に変換したい場合に用いるのが、「値の再割り当て」です。今までと同様に、変数の作成ボタンを押して、「値の再割り当て」タブを開きます。

そして、今までの値と新しい値をそれぞれ指定して、値を変換します。1点を5点に変えたい場合、「値を指定」のところに1を入力し、新しい値に5を入力して、「追加」を押します。あるいは、1点から3点を2点に変えたい場合、「範囲を指定」のところに1と3を入力し、新しい値に2を入力して「追加」を押します。特定の値を欠損値に変えたい場合は、欠損値に変えたい値を入れて、新しい値を「欠損値」に指定します。それ以外はそのままにしたい場合、今までの値を「その他すべての値」にして、新しい値を「今までの値をコピー」を選択します。設定が終わったら、OKボタンを押せば、変換された変数が出力されます。
◆変数の逆転
尺度を使う場合、逆転項目を含む場合も多いと思います。
そのような場合、尺度平均値を計算するためには変数を逆転しておく必要があります。変数の逆転は、尺度の最大値+1から得点を引けば実行できます。そこで、数値変換を使います。変数の作成ボタンをクリックして、「数値変換」タブを開きます。
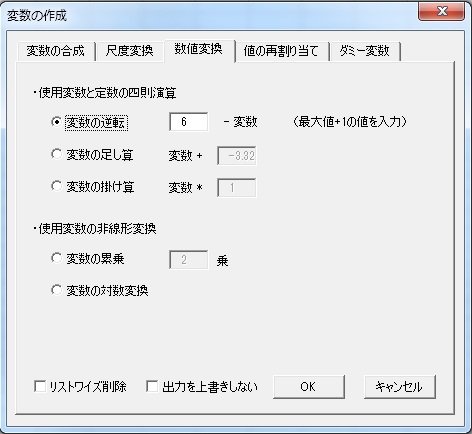
そこで、「変数の逆転」を選択し、尺度の最大値+1の値を入力します。デフォルトは5件法用に6としていますが、7件法の場合は8を、4件法なら5と入力してください。その後、OKを押せば逆転された変数が出力されます。
HADの基本的なデータハンドリングについての説明は以上です。
HADのサポートページを作りました。いわゆる「投げ銭」ですが、研究資金などにしようと思います。よかったらぜひ。