HAD9.00βをアップしました。
今回のバージョンアップで半端なく機能が増えました。
ほとんど別物です。
資料からダウンロードしてください。
追加した機能
因子分析
度数分布表とヒストグラム
クロス集計表
ノンパラメトリック検定
スピアマンの順位相関
偏相関分析
です。
一番の目玉は因子分析で、以下のような機能があります。
抽出法:最尤法、反復主因子法、主因子法、主成分法
回転法:プロマックス回転、バリマックス回転(その他オーソマックス回転)、プロクラステス回転
それ以外に、
信頼性分析:α係数とω係数、因子得点の信頼性を算出(逆転項目を因子負荷量から判断して逆転した場合の信頼性も出力)
尺度平均値:負荷している項目の平均値(逆転項目も逆転した値で出力可能)
スクリープロット:固有値の推移のグラフと、MAP(最小平均偏相関)を出力します。MAPが最も小さくなる因子数を抽出数とすることが推奨されています(堀先生のページを参照)。
など、結構便利機能がついています。
そのほかの機能については「続き」を参照ください。
HAD9用のマニュアルを作ったので、そこから抜粋して新機能について解説します。
○度数分布表:各変数の度数分布とヒストグラムを出力します。出力は”Freq”
度数分布表:欠損値を含めた度数と、欠損値を含めない有効度数および確率の両方を出力します。
ヒストグラム:有効度数を棒グラフにしたものを出力します。出現値の数が12を超える場合、12等分になるようにクラスを分割します。その場合、左側にクラスごとの度数を表にして、級代表値を出力します。
○クロス表:2変数のクロス表とノンパラメトリック検定結果を出力します。出力は”Cross”
クロス表:使用変数で指定した最初の2変数のクロス表を出力します。使用変数で最初に指定した変数を列、2番目に指定した変数を行にします。
相関係数:各尺度水準ごとの相関(連関)係数を出力します。名義尺度はクラメールの連関係数、順序尺度はスピアマンの順位相関係数、間隔尺度はピアソンの積率相関係数です。
ノンパラメトリック検定:平均順位を対象とした差の検定を行います。使用変数で最初に指定した変数を従属変数、2番目に指定した変数を独立変数としたときの分析を行います。独立変数が2水準ならマンホイットニーのU検定、3水準以上ならクラスカル-ウォリスのH検定を行います。
○相関分析:ピアソンの積率相関係数を出力します。出力は”Corr_test”
相関分析:相関行列と有意性検定結果を出力します。
相関行列:Amosなどの別のソフトウェアにデータとして投入したい場合に使います。
共分散行列:上と同じです。フォーマットはAmosにあわせていますので、そのままSEMなどの分析を実行できます。
順位相関:スピアマンの順位相関係数と有意性検定結果を出力します。出力は”Rank_test”
順位相関行列:スピアマンの順位相関係数をAmosフォーマットで出力します。”Rank”
※偏相関分析(変数の統制)について
HADでは、以下の画像のように使用変数に$を入力した場合、そのあとに指定した変数を統制変数として分析することができます。

このように指定した状態で相関分析を行うと、V3で統制したV1とV2の偏相関係数が出力されます。また、変数の統制は後述する回帰分析や因子分析、マルチレベル分析でも同様に行うことができます。つまり、偏相関行列を用いて因子分析などを行うことができます。
○媒介分析
媒介分析では、従属変数から独立変数への影響が、第三の変数によって媒介(仲介)されるかどうかを検討することができます。「階層的重回帰」のボタンをクリックし、「媒介分析」を選択すると実行できます。
bootn: 間接効果の検定で用いるブートストラップサンプルの数を指定します。デフォルトは1000で、50000まで指定できます。最小は200です。
以下の画像のように、独立変数として、Step1に2つだけ変数を入力します。最初に投入した変数が媒介変数、2番目に投入した変数が独立変数となります。
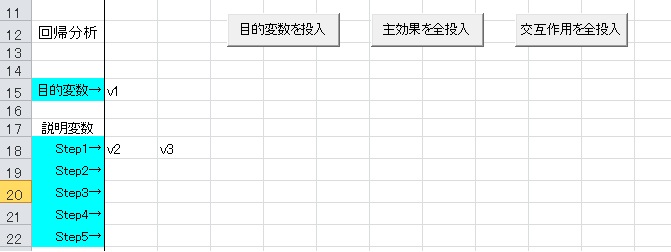
この場合、V1が目的変数、V2が媒介変数、V3が独立変数となります。V1←V2←V3といった媒介分析を行います。
○因子分析の方法
・「因子分析」のボタンをクリックすると、因子分析用の画面が表示されます。「分析実行」ボタンをクリックすると、因子分析が実行されます。出力は”Factor”
・使用変数に指定した変数を用いて因子分析が実行されます。
・因子数
因子数:因子数を指定します。「固有値1以上まで抽出」をチェックすると相関行列の固有値が1以上の因子数で分析を行います。
スクリープロット:「スクリープロット」をクリックすると、相関行列の固有値と、そのプロットを出力します。また、MAP(最小平均偏相関)を出力し、MAPの最小値に「←」を示します。MAPが最小になる因子数を選択することが推奨されます。
・因子抽出
抽出法:最尤法、反復主因子法、主因子法、主成分分析から選択できます。反復主因子法と主因子法は、SMC(重相関係数の2乗)を共通性の初期値として用います。
抽出基準:最大反復数と収束基準を設定できます。デフォルトは25と0.001です。因子分析が収束しなかった場合、これらの値を調整してください。
・因子軸の回転
回転法:斜交回転(プロマックス回転)と直交回転(バリマックス回転)から選択できます。また、仮説検証的回転として、プロクラステス回転(斜交あるいは直交)を選択できます。プロクラステス回転はデータセットを共分散行列に指定した場合のみ利用可能です。
回転基準:「斜交度」とはプロマックス回転を行うときにKappa(Power)です。この値が高いほど、因子間相関が高くなります。デフォルトは4です。3~5が最適とされています。
「重み」は、オーソマックス基準のωです。この値が1のとき、バリマックス回転になります(デフォルト)。そのほか、
0 =クォーティマックス回転
0.5 =バイクォーティマックス回転
因子数÷2 =エカマックス回転
項目数 =因子パーシモニー回転
重みを大きくするほど各因子の寄与率が均等に近くなります。
カット:この値より大きい因子負荷量のみ、信頼性係数の計算に用います。デフォルトは0です。
・出力オプション
サイズ順に並び替え:因子負荷量の絶対値が大きい順に並び替えます。
相関行列:因子分析に用いる相関行列を出力します。
因子得点:回帰法によって推定された因子得点を出力します。
尺度平均値:因子に負荷した項目のみを用いて平均値を計算します。また、逆転項目(因子負荷量が負の項目)がある場合は、逆転する方法を選択できます。
下の画像が因子分析の画面です。
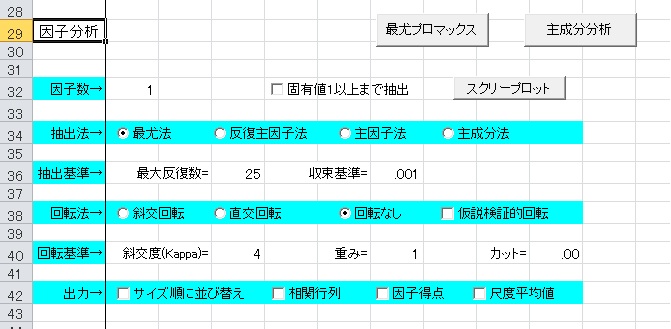
因子分析の出力
因子パターン:因子パターン行列を出力します。
適合度:最尤法を選択した場合、データとの適合度を出力します。因子数決定の参考になります。
信頼性係数:α係数とω係数、因子得点の信頼性を出力します。ω係数は因子分析のモデルが適切である場合、α係数よりも大きくなります。ω係数がα係数よりも小さい因子がある場合、因子数をさらに増やすことが推奨されます。因子得点の信頼性は、α・ω係数よりも常に大きくなります。
因子間相関:因子間相関を出力します。直交回転の場合は出力されません。
因子構造:因子構造行列を出力します。直交回転の場合、因子パターンと因子構造は一致するので
因子構造行列は出力されません。