HAD11.1から,ロバスト回帰分析が実行できるようになりました。
ロバスト回帰分析とは,簡単に言えば,外れ値の影響を小さくして回帰係数を推定する方法です。
こちらの記事が参考になります。以下は,僕なりの解説ですが,興味あれば読んでみてください。
ロバスト回帰分析の概要
HADに搭載しているのは,M推定によるロバスト回帰分析です。MM推定はまだ搭載していません。
M推定は,残差が大きいものの重みを特定の関数を用いて小さくして,重みつき最小二乗法でパラメータを推定します。そして,新たに残差を計算→重みつき最小二乗法で推定→残差を計算を繰り返して,収束するまで計算します。いわゆる,反復重みつき最小二乗法です。
このようにして推定された結果は,従属変数の外れ値に対してロバスト(頑健)な推定値になります。
下の図は,外れ値を含んだデータの散布図です。外れ値が右上に2つあるのがわかると思います。赤い線が普通の回帰分析の結果,青い線がロバスト回帰分析の結果です。赤い線は外れ値の影響を受けた回帰直線になっており,青い線は外れ値以外のデータによくフィットしているのがわかると思います。

このデータはirisデータの一部を使っていますが,元のデータから二つだけ10を足したものを使っています。
元のデータの回帰直線はb=0.542なのに対し,外れ値をそのまま計算した回帰係数(赤い線)はb=5.117と,元の係数とかなり値が変わってしまっています。ロバスト回帰分析の回帰直線はb=1.134と,やや影響は受けていますが元の値と近い推定ができています。
ロバスト回帰分析のいろいろ
ロバスト回帰分析には,従属変数の外れ値に対して頑健なM推定に加え,独立変数の外れ値に対しても頑健なMM推定があります。MM推定は,M推定の効率性を維持したまま,独立変数に対する頑健さも備えているので,とても良い推定方法です。ただ計算がやや複雑になります。
また,外れ値に対する重みのつけ方にもいろいろな方法があります。よく使われるのはTukeyのbiweightと,Huberの方法の二つです。
Tukeyの方法は一定以上大きい残差の重みを0にするのが特徴で,また回帰直線からは少しでも離れると重みが小さくなります。
一方,Huberの方法はある一定までは重みが1なのでペナルティはなく,一定以上から大きくなると徐々に重みが小さくなります。いくら残差が大きくても,重みが0になることはありません。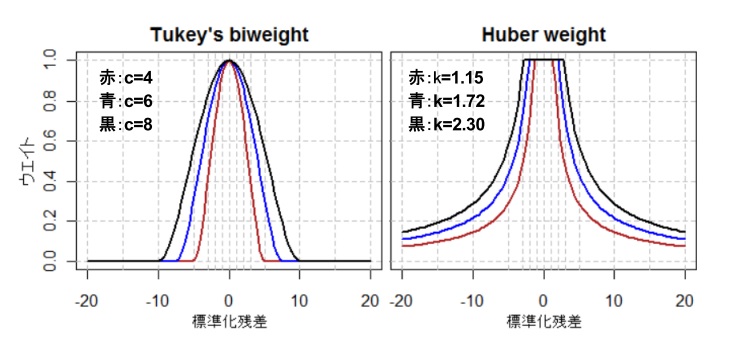
和田(2012) 多変量外れ値の検出 繰り返し果汁最小二乗法による欠損値の布袋方法 統計研究年報, 69, 23-52.から引用。
また,それぞれの関数の閾値もパラメータとして変更することができます。ただ,漸近有効性が95%になるポイントというのは,だいたいわかっているのであまり変更されることはありません。
なお,HADはHuberの関数を使っています。
ロバスト回帰分析の実行
Rでロバスト回帰をするには,MASSパッケージのrlm関数を用います。基本的には回帰分析の関数,lm関数と同じ使い方で実行できるのでお手軽です。
method ="M"とすればM推定,"MM"とすればMM推定になります。
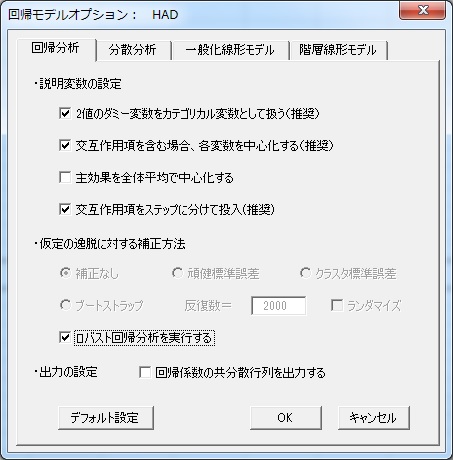
HADでロバスト回帰分析を実行するためには,オプションボタンの「ロバスト回帰分析を実行する」にチェックすれば,回帰分析がロバスト回帰分析になります。