今回は、HADで因子分析を実行する方法についてまとめておきます。
HADでは、抽出法は以下の方法から選べます。
- 最尤法
- 最小二乗法
- 反復主因子法
- 主成分法
- カテゴリカル因子分析
最尤法は、得られたデータが最も得られやすいような因子モデルを推定する方法です。尤度を最大にするから最尤法。最尤法は、尺度不変(変数の単位を変えても、因子構造は変わらない)という望ましい性質を持っています。また、因子と項目の正準相関係数を最大にする方法でもあります。ただし、解が収束しなかったり、共通性が1を超える(不適解)などの問題も多く起こります。
最小二乗法は、相関行列と因子モデルの誤差の2乗和を最小にする方法です。最尤法に次いでよく使われる方法です。最尤法に比べて不適解は少ないです。ただし、尺度不変ではありません。
反復主因子法は、SMC(重相関係数の2乗)を共通性の推定値として用いて、固有値を繰り返して収束するまで計算する方法です。上手く収束すれば最小二乗法と同じ解になります。ただ、収束までに時間がかかります。また、共通性が1に近づくとほとんど解が変化しなくなりますが、最適解には程遠いということがあります。最小二乗法でも不適解が出る場合に、それらしい解を出したいときに使うといいでしょう。
反復しない主因子法は、1度だけ固有値計算をする方法です。あとは反復主因子法と同じです。
計算が速く済み、不適解はほとんどでません。ただし、共通性の推定はあまり妥当ではありません。
※HAD9.3からは、選択できなくなりました。ただし、反復主因子法で最大反復数を1にするとこの解になります。
主成分法は、主成分分析と同じ方法です。共通性を1として推定して、固有値を計算します。必ず収束し、計算が速いのが強みですが、共通性の推定は正しくありません。
カテゴリカル因子分析は,変数が連続データではなく,順序尺度であるような場合にも適用できる方法です。変数が2値や3値の場合にも,妥当な因子構造を推定してくれます。推定方法は重みつき最小二乗法という方法を用います。
因子軸の回転は、以下の方法から選べます。
1.直交回転
バリマックス回転を含む、直交回転を選択できます。直交基準を変えることで、クォーティマックス回転やエカマックス回転などを選べます。直交基準は値を大きくすると、因子寄与率が均等に近くなります。デフォルトは1で、バリマックス基準です。
2.斜交回転
斜交回転は、プロマックス回転、直接オブリミン回転、独立クラスター回転から選択できます。
・プロマックス回転
直交回転をターゲットにした、プロクラステス回転を行います。いわゆるプロマックス回転はバリマックス回転をターゲットとしますが、HADではクォーティマックスやエカマックス解などもターゲットにすることができます。斜交基準を変えることで、因子間相関の大きさが変わります。大きくすると、因子間相関も大きくなります。デフォルトは4で、SPSSと同じです。なお、SASのデフォルトは3です。
・直接オブリミン回転
オブリミン基準を最小にする回転法です。オブリミン基準は、簡単に言えば因子間の因子負荷の共分散の総和です。オブリミン回転は、ある程度因子構造の複雑性を許容するので、比較的データに適した解を出します。因子間相関はプロマックス回転よりも小さめです。
・独立クラスター回転
Harris-Kaiser回転とも言われます。他の方法より完全クラスター解(負荷している因子は一つだけで、他は負荷量が0になる)に近くなります。つまり、単純構造に最も近くなります。因子間相関はプロマックス回転よりも大きめです。
3.プロクラステス回転(共分散行列による分析時のみ可)
ターゲットにした因子負荷行列に最も近くなるように回転する方法です。先行研究の因子負荷に近づけることができます。直交と斜交の両方が選べます。具体的にHADで因子分析を実行する方法は、続きを参照してください。
HADでは、因子分析を実行するときに2つの方法が選べます。
1つは、ローデータから分析する方法。もう1つは共分散行列から分析する方法です。ローデータから分析すると、データを読み込むのに時間がかかります。共分散行列から分析すると、計算時間は早いですが、因子得点を計算できません。因子得点を算出したい場合はローデータ、それ以外は共分散行列から、といった感じで使い分けるのがいいでしょう。
◆ローデータから分析する方法
最初に、「因子分析」というボタンを押して、因子分析用のプロシージャを開きましょう。そして下の図のように、使用変数に分析に使用する変数名を指定します。今回は10項目で2因子のモデルを想定します。
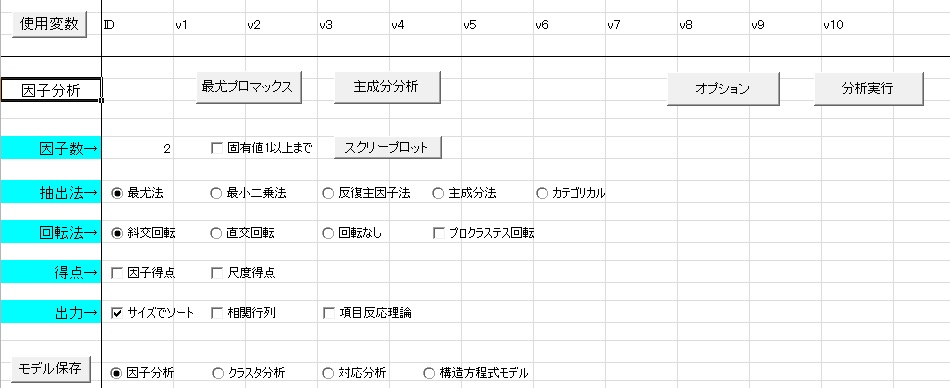
※HAD12の画面です。
因子数は、固有値1以上の因子を指定したい場合は、「固有値1以上まで抽出」にチェックします。そうでない場合は、因子数→ のところに、数値を指定します。また、因子数決定の参考のため、スクリープロットを出力できます。「スクリープロット」を押すと、「Scree」というシートに下の図のようなプロットが出力されます。
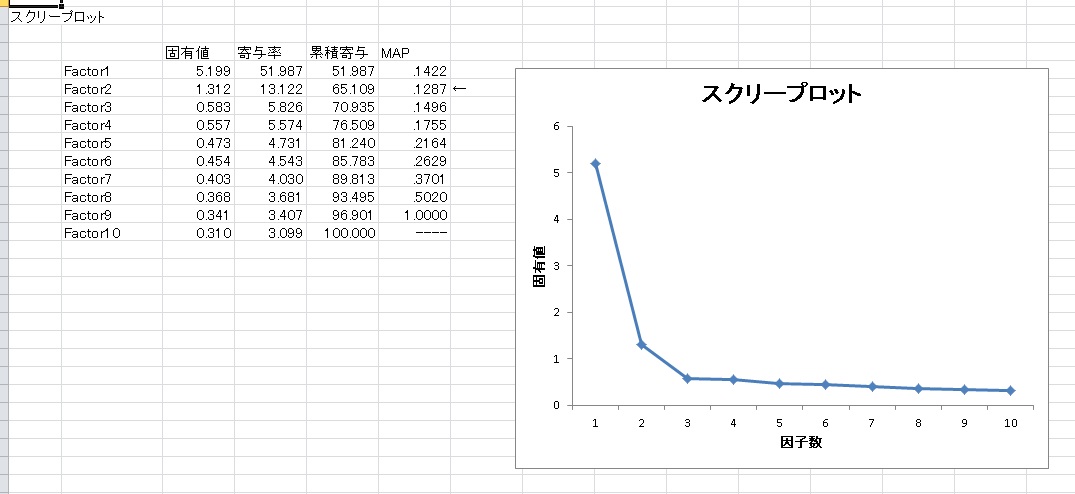
固有値の推移を表示します。このとき、MAPは因子数の決定に役立ちます。MAPが最も小さい因子数が、因子が最もうまく相関行列を説明できていることを示しています。ただし、必ずしもMAP基準が正しいわけではありません(因子数を少なめに提案する傾向がある)。
また、スクリープロットボタンの隣にある「平行分析を実行する」というチェックボックスをチェックしてスクリープロットを表示すると、平行分析を実行します。平行分析など他の因子数決定のための基準については、こちらの記事に詳しく解説しています。今回のデータでは2因子が提案されているので、2因子解を採用してみます。
モデリングシートに戻って、実際に因子分析をしてみます。抽出法は最尤法、回転法はプロマックス回転がお勧めです。「最尤プロマックス」というボタンを押すと、自動的にそれが選択されます。なお、「主成分分析」を押すと、主成分法の回転なしが選択されます。

上の図は、因子分析の結果です。最尤法を選択した場合は適合度が出力されます。CFIは.95以上、RMASEAは.05以下である場合、モデルはデータに適合しているといえます。今回のモデルは非常に適合しています。このとき、因子分析が収束しなかったり、共通性が1を超えるなどの不適解が得られた場合、赤字で警告します。その場合は、最大反復数をオプションで増やしたり、モデルを変更するか抽出法を変えるなどの工夫が必要です。
次に、下の図のように各因子の信頼性を出力します。
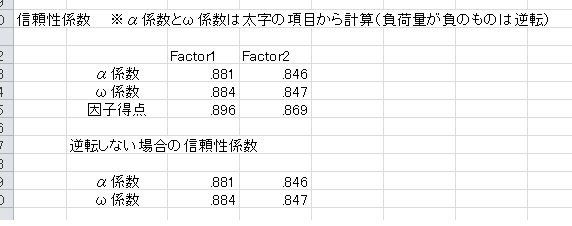
α係数は、太字の項目を平均した場合の内的一貫性を示しています。.80以上であれば信頼できるといわれています。ω係数は、α係数をよりも正確に信頼性を推定します。因子分析が適切であれば、α係数よりもω係数は大きくなります。因子得点の信頼性は、回帰法を用いた場合の信頼性の推定値です。
このとき、αやω係数は、因子負荷量の符号を基に、負の項目を自動で逆転した場合の信頼性を計算します。逆転する前の信頼性は、下に表示しています。
また因子得点を出力したい場合は、因子得点と尺度平均値が選択できます。因子得点は回帰法で推定します。尺度平均値は、項目は因子負荷が最も高い因子に負荷していると仮定して、それぞれの因子に該当する尺度の平均値を算出します(因子分析表の、太字の項目を平均する)。
尺度平均値の算出で、負荷量が負の項目が含まれている場合、以下の図のように、逆転するかどうかを尋ねるウィンドウが表示されます。
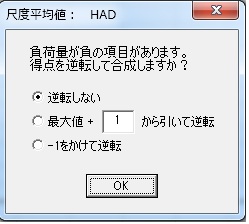
逆転項目が含まれていて、因子分析でも負荷量が負の項目がある場合は、この機能を使えば簡単に尺度平均値を算出することができます。
ローデータの分析法は以上です。次回は、共分散行列を使った因子分析の方法について解説します。
HADで因子分析(共分散行列を使った分析+プロクラステス回転)