先日,HAD13.02に搭載された,連続変量に対する潜在ランク分析のコードをRに翻訳してみました。
コードはこちらです。
このコードでは,複数の連続変量を与えることで,参加者を潜在的な順序グループに分類する分析を行います。なお,潜在ランク分析そのものについてはこちらの記事を参照してください。
推定は,生成位相マップ(Generative Topographic Mapping: GTM)を用いて推定しています。簡単に言うと,混合分布モデルに順序の制約を与えたものです。いまのところ,連続変量のみが対応しています。順序尺度版も気が向いたらやりますが,今のところ難しいと思います(HADでは実装されています)。
なお,この潜在ランク分析とこの関数については,2月14日に比治山大学で行われるHiroshimaR#3で発表予定です。興味ある方はぜひお越しください。
◆分析例
それでは2014年のプロ野球選手,打者99名(年俸上位100名から0打席の一人を除外)を対象を分析したものを例に,関数の使いかたについて簡単に説明します。
なお,上記のサンプルデータはここにあります。
まず,データをdatに読み込みます。
dat <- read.csv("baseball.csv")
データには,打率,安打数,本塁打数,打点の4つを入れてます。
head(dat)
|
1 2 3 4 5 6 7 |
AVG HIT HR RBI 1 0.248 114 19 57 2 0.300 170 19 68 3 0.221 99 24 71 4 0.338 180 14 84 5 0.257 98 34 90 6 0.313 172 8 73 |
次に,潜在ランク分析を実行するための関数を読み込みます。
source("latent_rank.r")
潜在ランク分析は,LRA()という関数で実行します。引数は,データセット,ランク数だけを入力すればOKです。今回は,5ランクで推定してみましょう。結果はsummary関数にいれます。
result <- LRA(dat, 5)
summary(result)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Latent frequencies: rank 1 rank 2 rank 3 rank 4 rank 5 13.798 21.389 27.217 12.982 23.615 Means: AVG HIT HR RBI rank 1 0.210 9.098 0.399 4.769 rank 2 0.236 35.623 2.658 18.906 rank 3 0.266 102.687 4.985 36.486 rank 4 0.264 106.136 15.957 57.726 rank 5 0.293 144.374 19.027 77.166 Rank correlations: AVG HIT HR RBI 0.621 0.880 0.785 0.939 |
すると,上のように各ランクの潜在度数,ランクごとの各変数の平均値,潜在ランクと変数の順位相関係数が出力されます。
潜在度数は,潜在確率にサンプルサイズをかけたもので,各ランクに何人いるかを表しています。今回の例ではそこそこ散らばっているようです。
平均値を見ると,ランク1は打率が2割1分,9安打,0.4本塁打,4.7打点と,へぼへぼ選手であることがわかります。ランク3ぐらいになるとそこそこに,ランク5になるとかなりの成績になってきます。
潜在ランクとの順位相関は,各変数がどれほどランクの推定に貢献しているかがわかります。今回のランクは打点と高い相関があるようです。
続いて,plot関数に結果を入れると,次のようなグラフが出力されます。
plot(result)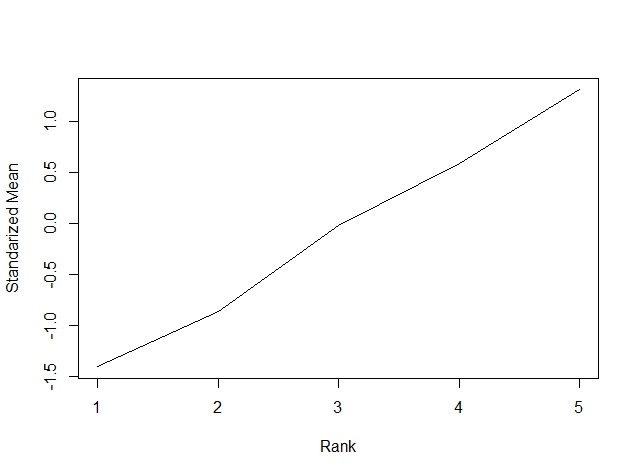
このグラフは,ランクによる主成分得点の推定値です。この主成分得点が小さいランクほど小さい値になることが,ランクの順序配置の条件としています。
次に以下のように変数の番号を入れると,変数ごとのプロットを見れます。3番めの本塁打のプロットを見てみましょう。
plot(result,3)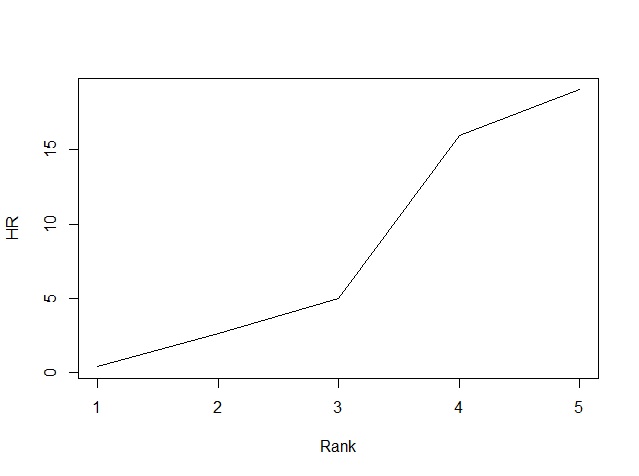
ややガタついていますが,順序性は保持されています。なお,各変数については順序配置が満たされないこともあります。
情報量規準を見る場合は,AIC関数に入れます。
AIC(result)
|
1 2 |
AIC BIC SBIC [1,] 1970.077 2084.262 1945.308 |
情報量規準を見ることで,何ランクが適切であるかが推定できます。実は,このデータの場合,5ランクがAIC最小になります。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
> result <- LRA(dat, 4) > AIC(result) AIC BIC SBIC [1,] 1980.432 2071.261 1960.729 > result <- LRA(dat, 5) > AIC(result) AIC BIC SBIC [1,] 1970.077 2084.262 1945.308 > result <- LRA(dat, 6) > AIC(result) AIC BIC SBIC [1,] 1982.178 2119.72 1952.343 |
なお,各参加者のランクを知りたい場合は,
rank5 <- result$rank
rank5
|
1 2 3 |
> rank5 [1] 4 5 4 5 5 5 5 1 5 5 4 4 5 5 5 5 4 4 2 1 5 5 3 5 3 5 4 3 2 1 5 3 3 2 2 2 2 2 2 5 3 5 1 1 2 3 3 3 3 3 2 1 2 3 3 2 4 [58] 2 3 3 2 4 4 3 3 3 1 1 3 3 5 2 5 4 1 2 1 1 2 2 3 5 5 3 5 5 2 4 2 3 1 4 3 3 1 2 2 3 1 |
また,各参加者の潜在ランクへの所属確率(負担率)を知りたい場合は,
syozoku <- result$res
で知ることができます。
その他オブジェクトは,対数尤度が"ll",分散が"vars",混合確率が"prob",収束回数が"count",などです。