GWですね。僕の本務校は普通に授業日です。さっき授業してきました。
空き時間に、最近取り組んでることの関係のネタを記事にしておきます。
確率密度関数を推定する
データを取ったとき、分布をみますよね。主にヒストグラムで。今日(5月4日)はスターウォーズの日らしいので、銀河データを例にしてみます。データはこちら(11.8.1)からとれますが、松浦健太郎さんのブログからRdataでダウンロードもできます。
データの読み込み
|
1 2 |
load("data.RData") dat <- data$velocity |
ヒストグラムを表示してみましょう。
|
1 2 3 4 |
library(ggplot2) df <- data.frame(dat) %>% ggplot df + geom_histogram(aes(x=dat,y=..density..),bins=30,fill="gray",color="black") |
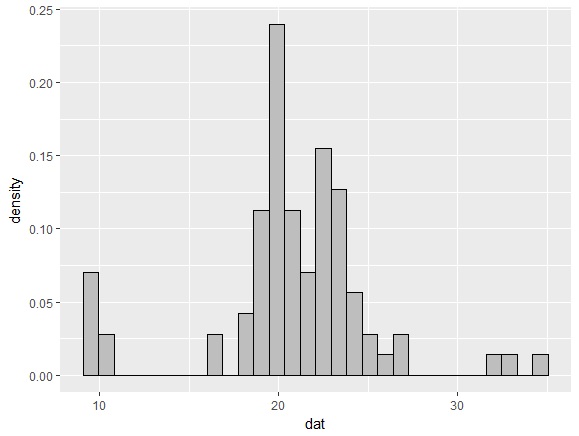
これでもなんとなく分布の感じはわかるのですが、ヒストグラムの欠点は幅をどういう間隔でとるかによって見え方が変わるという点です。たとえば、30区切りを15区切りに変えると・・・
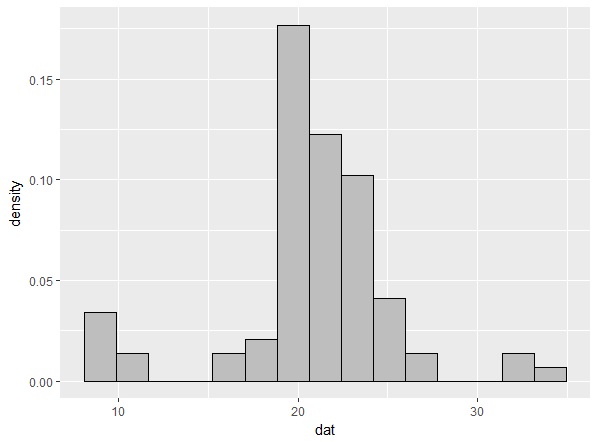
このように、二峰に見えた真ん中部分が単峰になってしまいます。また、棒グラフだとガタガタで、分布の形がどうなってるのか、アバウトにしかわからないという問題もあります。
そこで、カーネル密度推定という方法が便利です。これは、なめらかな曲線で分布を推定する方法です。
|
1 2 |
df <- data.frame(dat) %>% ggplot df + geom_density(aes(x=dat),fill="gray",color="black",adjust=1) |
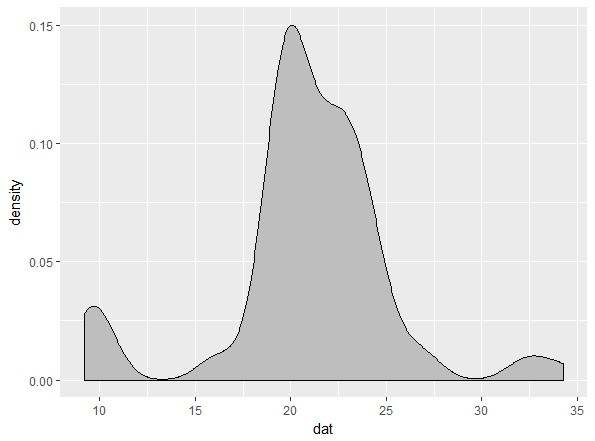
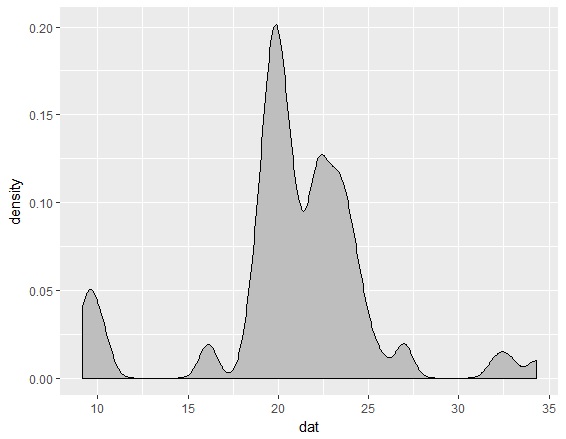
しかし、カーネル密度推定も、バンド幅とよばれるハイパーパラメータがあって、これでなめらかさがかわります。ggplot2のgeom_densityのadjustを0.5に変えると次ようになります。
確率密度関数をベイズ推定したい
というわけで、データの分布(つまりは確率密度関数)をベイズ推定したい。できればハイパーパラメータもデータから学習したい。こういうことができると楽しいですね。
確率密度関数を推定する方法はたぶんいろいろありますが、ここではロジスティックガウス過程を使った方法を紹介します。この方法自体もいろんな論文で提案されていますが、MCMCで推定する方法としては、Riihimäki & Vehtari(2014)の論文が参考になります。
ロジスティックガウス過程は、まず密度関数pi(x)がロジスティック密度変換によって与えられると仮定します。xはデータです。
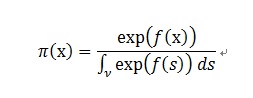
続いて、f(x)がなめらかになるように、ガウス過程事前分布に従うと仮定します。つまり、
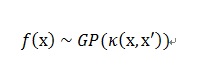
κ()は共分散行列で、いろんなカーネル関数が仮定できますが、ここではガウスカーネルを仮定することにします。
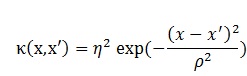
ここで、ηとρはハイパーパラメータで、ηは分散の大きさを、ρがなめらかさを表します。
ただし、上のロジスティック密度変換は積分を含むため、計算が難しいです。そこで十分大きなK個に離散化します。重みはすべて等しいとすると、pi_kは次のソフトマックス関数で表せます。
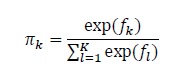
pi_kは離散化された分布の確率なので、確率質量関数になります。Kを十分大きな数にすれば、なめらかな分布の推定が可能になるというわけです。
データをK個に区切った各ポイントをzとします。zはデータの最小値から最大値をK個に区切った値を使えばいいです。データ数が82なので、Kも82にしてみます(一致する必要はありません)。データ数よりも大きく区切っても推定できますし、少なくてもいいです。50あればそこそこなめらかになります。100あると綺麗に見えます。
確率モデルは、データxが、混合正規分布(ここで仮定する分布は連続的なものであればなんでもいいですが、正規分布以外である必要もないので)に従うとします。その混合比率piが上のソフトマックス関数で得られるとします。そしてデータxは、平均z_k、SDがσの混合正規分布に従うため、尤度関数は、
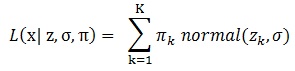
となります。
Stanでの実装
これをStanでやってみます。Stanコードは以下です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
data{ int N; int K; vector[N] x; vector[K] z; real rho; real eta; } transformed data{ vector[K-1] Mu = rep_vector(0,K-1); } parameters{ vector[K-1] pi_raw; real //real //real } transformed parameters{ simplex[K] pi; cov_matrix[K-1] Cov; real log_lik[N]; #pi pi = softmax(append_row(pi_raw,0-sum(pi_raw))); #kernel function for(i in 1:(K-1)){ for(j in 1:(K-1)){ Cov[i,j] = eta^2*exp(-(z[i]-z[j])^2/(rho*sd(x))^2); if(i==j) Cov[i,j] = Cov[i,j] + 0.1^2; } } #likelihood function { vector[K] ps; for (n in 1:N){ for (k in 1:K){ ps[k] = log(pi[k]) + normal_lpdf(x[n]|z[k],sigma); } log_lik[n] = log_sum_exp(ps); } } } model{ #prior pi_raw ~ multi_normal(Mu,Cov); sigma ~ student_t(4,0,2.5); //rho ~ student_t(4,0,2.5); //eta ~ student_t(4,0,2.5); #likelihood target += sum(log_lik); } |
piはガウス過程に従うpi_rawをソフトマックス関数に入れたものから計算しています。ただ、K個のpiを推定するのに必要なpi_rawはK-1個(1つ冗長になる)なので、その点に注意が必要です。
ハイパーパラメータのηとρはデータからも学習できますが、データ数が少ないとうまく収束してくれません。今回は外部からハイパーパラメータを与えるバージョンでやってみます。なお、ρはデータのスケールがどんな場合でも同じような値になるように、ガウスカーネルのところにxのSDを入れています。また、カーネルの対角項に微小値を足しているのは、計算を安定させるためです。
Rコードは以下です。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#stan model model <- stan_model("density.stan") #setting K <- length(dat) N <- length(dat) temp <- (max(dat)-min(dat))*(1/25) z <- seq(min(dat)-temp,max(dat)+temp,length.out=K) datadens <- list(N=N,K=K,z=z,x=dat,rho=0.6,eta=2) #sampling fit <- sampling(model,data=datadens,iter=1000,warmup=500,chains=4,cores=4) |
上のコードでは、zを最小値から最大値ではなく、少しだけ最小値から小さい値から、少しだけ最大値から大きい値までの値を使ってます。そうした方が図がきれいに見えるから、というだけで、特に大きな意味はありません。
データ数Nと離散化する数Kの大きさによって推定時間は大きく変わります。今回のモデルだと20分ぐらいでサンプリングできます。
結果はこんな感じになります。
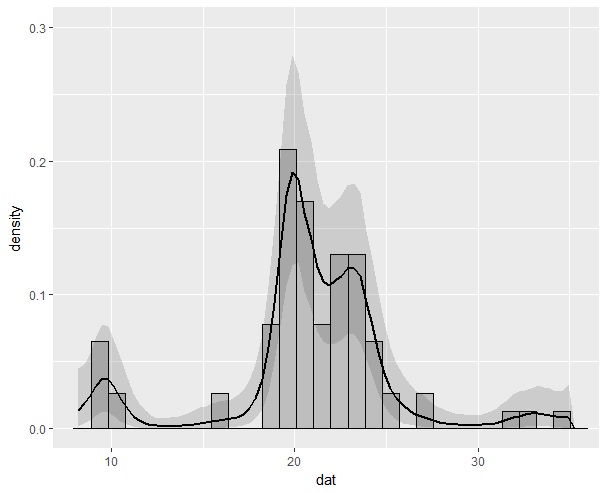
カーネル密度推定に比べての長所は、95%ベイズ信頼区間が推定できること、ハイパーパラメータを情報量基準やクロスバリデーションなんかの外的な基準で良し悪しを判断できること、などがあると思います。データ数が多くなれば、ハイパーパラメータはデータから推定できます。1000ぐらいのNがあれば十分じゃないでしょうか。推定時間はそれなりにかかるので、実用的かといわれると・・・まぁお好みで。
ハイパーパラメータについてですが、ηは2ぐらいでいいと思います。問題はρのほうで、この値によって分布の滑らかさが大きく変わります。今回のデータだと、0.6ぐらいでWAICが小さくなった(あまり正確に検証してませんが)ので、こうしました。ADVIをつかえば計算が早いので、それでρのあたりをつけてからMCMCすればいいのかもしれません。
以上、僕のGWでした。