次は、HADの分散分析で単純効果を検定する方法です。
◆プールされた誤差項と水準別誤差項
単純効果の検定には、2種類のやり方があります。それは誤差項の扱い方で、「プールされた誤差項」と「水準別の誤差項」の2つです。単純効果の検定では、群分けする要因の各水準ごとの、別の要因の効果を検討します。そのさい、各水準の誤差を等しいと考えるか、異なると考えるかで方法が変わるわけです。
まず、一般的に分散分析では「各水準の誤差分散は等しい」、という仮定を置いています。なので分散分析の発想からすると、すべての水準で同じ誤差項を使って検定を行うのが基本です。
これを「プールされた誤差項」と呼ぶことがあります。プールするとは、全水準でひとまとめにする、ぐらいに考えてもらってOKです。プールされた誤差項を使うと、全水準をまとめた誤差を使うので自由度を減らすことなく検定できます。たとえば、参加者間計画で、10人のサンプルがいて、実験条件が5人、統制条件が5人だったとします。この場合、単純効果検定でも10人分のサンプルを使って検定を行うことができるわけです。
一方、各水準で分散が等しいと仮定するのは無理がある場合もあります。あるいは、実験条件の単純効果を検定するのに、異質な統制条件の情報を使うのは変だ、という考え方もありえます。このような場合、各水準ごとに分散分析をしてやって主効果を見ることで、単純主効果を検討するというやり方を採用することも可能です。これを「水準別誤差項」による検定と呼ぶことがあります。水準別誤差項は、各水準ごとのサンプルのみを使うので、その分自由度が減ります。
どちらがいいのか、難しい問題です。分散分析の主効果は、基本的に各水準の分散が等しいという仮定で検定しているので、単純効果の検定の場合だけ異分散を認めるというのも、一貫していない態度であるように思えます。
まとめると、
- プールされた誤差項:各水準の分散が等しいと仮定して、自由度を減らさずに検定→検出力が高いが、水準ごとに分散が大きく異なる場合、妥当な検定結果を示さない
- 水準別誤差項:各水準の分散が異なると仮定して、自由度を減らして別々に検定→検出力は低いが、水準ごとに分散が大きく異なる場合でも妥当な結果を示す。
HADでは、検出力が最も高い(ある意味理想的な状態)をデフォルトにしていますので、「プールされた誤差項」による単純効果検定をデフォルトで行います。オプションで水準別誤差項を選択することもできます。
では、「続き」では具体的な方法を書いていきます。
さて、まず前回と同じデータセットを使います。
今回は、3要因混合計画を例に、単純効果検定のやり方を説明します。
まず、参加者間要因であるaとb、参加者内要因の変数であるx1~x4を使用変数に指定します。そして、下の図のようにx1~x4を目的変数に指定し、$マークの後に任意の要因名(ここではc)を入力し、「交互作用を全投入」ボタンをクリックします。

このとき、単純効果検定をするためには、群分けする要因(スライス要因)を「スライス→」の行に記入します。たとえばa要因の水準1と水準2のそれぞれについて単純効果を見たい場合、スライス変数のところにaと書きます。
この状態で「分析実行」を押すと、"Anova"が出力されたと、"Slice"が続いて出力されます。

上の図のように、単純効果分析の結果が出力されます。
「a=1」とあるのは、a要因の水準1の場合、という意味です。水準番号は、参加者間要因の場合は入力されている数値が、参加者内要因の場合は水準の順番(1番目の場合は1)が出力されます。
ここで、「単純主効果の自由度補正」という言葉があると思いますが、これはプールされた誤差項を使用した時だけ関係します。
プールされた誤差項による単純主効果の検定において、スライス変数が参加者内要因の場合、誤差項は単純効果を見る要因の誤差項と、スライスする要因の誤差項を合成した誤差項を用います。このとき、異質な分散を合成するので、正しい検定をするためにはSatterthwaiteの方法による補正が必要となります。もし合成する誤差分散が等質なら補正の必要はありません。デフォルトは補正なしですが、気になるようでしたらオプションの「Satterthwaiteの補正を行う」にチェックをしてください。 HAD10から,常に補正するようにしました。
上の図では「プールされた誤差項」による単純効果分析を示していますが、水準別の場合は下のようになります。
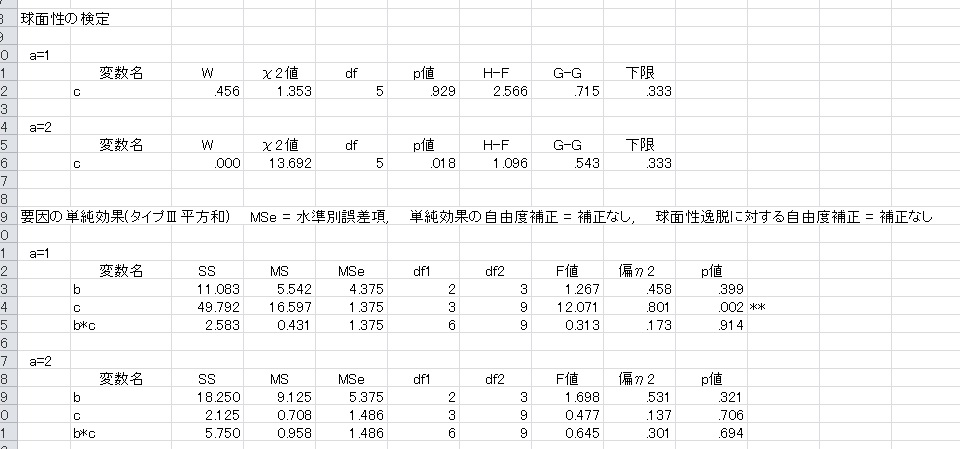
自由度が水準別の場合は半分になっているのがわかると思います。その分検出力は下がっているわけです。
単純効果分析でもグラフは出力されます。以下のように、交互作用のパターンがすぐわかります。
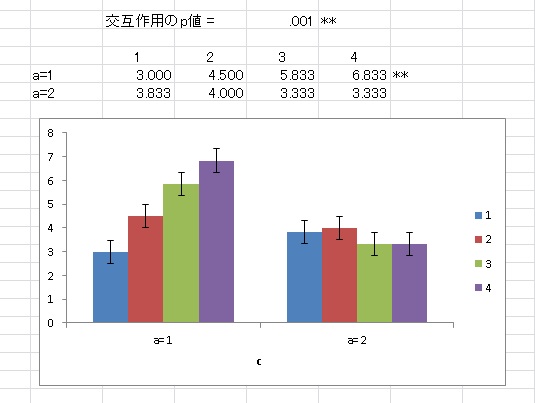
次に、単純・単純効果分析のやり方です。例えば、a*b*cの交互作用が有意だったとき、c要因の単純・単純主効果が検定したい場合は、スライス要因としてaとbの両方を指定します。以下の図のように、それぞれを別のセルに指定します。

すると、以下のような結果が出力されます(下の例は水準別誤差項の場合)。

分散分析のやり方は以上です。