HAD9.3から、クラスター分析が実行できます。
クラスター分析とは、データから距離を計算し、その距離関係からグループ(クラスタ)を作っていく方法です。距離が近い人から順にクラスタを作っていき、最終的に一つのクラスタになります。
そのクラスタ化のプロセスを見て、いくつかのグループに分けるのがクラスター分析の目的です。
それでは、HADでクラスター分析をする方法を続きに書いておきます。
今回は豊田先生の「データマイニング入門」のクラスター分析の章にあるデータ(ちょっとだけ改変)を例に、HADでの実行方法を紹介します。
HADの基本的な使い方は、こちらを参照してください。
◆クラスタ分析の方法
まず、以下のようなデータを使います。
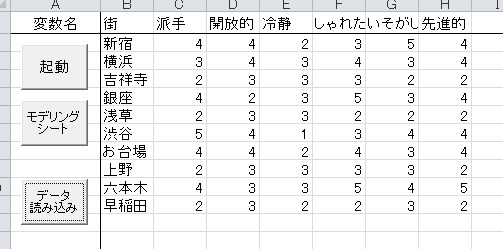
東京の街について、派手、開放的、冷静といった形容詞について当てはまる程度を評価したデータです。
これらのデータを用いて、東京の街をグループ分けしてみましょう。
このデータを読み込んで、以下のように使用変数に指定します。

クラスタ分析は、「因子分析」とあるオプションボタンを押して、そのあとクラスタ分析を選ぶと、実行可能です。
クラスタ分析では、分類するのが変数なのか、サブジェクト(回答者)なのかを選択できます。
今回は街をクラスタリングするので、「回答者を分類」ボタンを押します。すると、それに最適なオプションが自動で選ばれます。手動で変更することも可能です。
「使用データ→」とあるところには、距離行列をどのように計算するかを選択します。ローデータはそのままで、標準化は標準化したデータで距離行列を作成します。単位が異なる変数が含まれているときは標準化を選択するといいでしょう。
ではこの状態で「分析実行」ボタンを押してみます。すると、次のような結果が出力されます。

事前にクラスター数を指定していれば、各クラスターに所属するメンバーが表示されます。
クラスタ1には新宿、横浜、銀座などのにぎやかな街が、クラスタ2には吉祥寺、浅草といった落ち着いた街が所属しています。各クラスタがどういう特徴を持っているかを知るためには、「クラスタの特徴」をチェックしておくと便利です。
以下のような結果が出力されます。
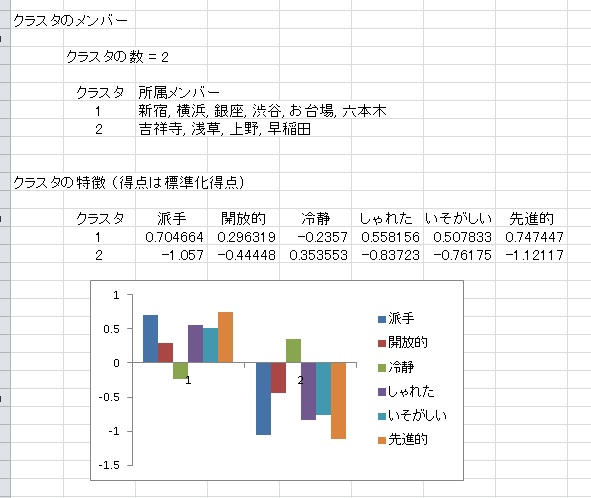
クラスタ1は派手で先進的なイメージが強く、クラスタ2は冷静なイメージがあることがわかります。
次に、クラスタ数の決め方です。クラスタ分析ではデンドログラム(樹形図)をみて、クラスター数を決定することが多いです。「デンドログラムを描写」をチェックしておけば、以下のようなデンドログラムが出力されます。
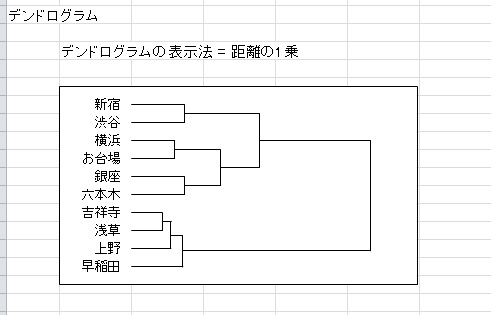
これをみれば、大きく分けて2つのクラスタがあることがすぐわかります。
クラスタ1も、新宿・渋谷は特に近く、横浜やお台場、銀座とは少し違っていることがわかります。
今回はサブジェクトを分類する方法を書きましたが、変数も同様の方法で分類できます。
◆クラスタ分析のオプション
クラスタ分析にも、いくつか分析手法があります。
それらを選択するには、「オプション」ボタンを押して、以下のウィンドウを開くと可能です。
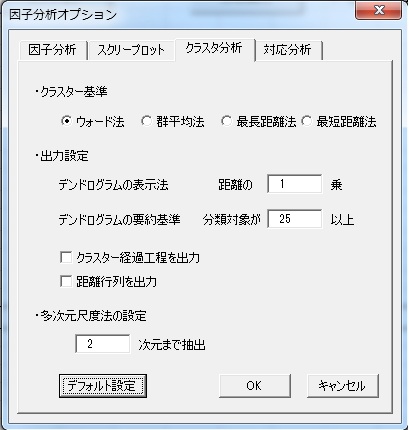
それぞれの方法について簡単に説明します。
- ウォード法が最も安定していて、クラスタリングが解釈しやすい結果を出すようです。
- 群平均法はユークリッド平面を仮定しなくてもいい方法で、そこそこ良い結果を出します。
- 最短距離法は一つずつ大きなクラスタに吸収されるようなデンドログラムになり、使いにくい方法です。
- 最長距離法は、ユークリッド平面を仮定しておらず、かつ順序距離でも適用可能なので、場合によっては使いやすいです。
全体的には、ウォード法がお勧めです。
◆多次元尺度法
クラスタ分析と同様に、距離行列を使って分析する方法に多次元尺度法があります。多次元尺度法は、距離行列から2次元空間の座標を計算する方法です。「出力→」のところにある「多次元尺度法」をチェックしておくと、同時に分析結果が出力されます。
街のデータを多次元尺度法を用いて2次元にマッピングしてみると、以下のようになります。
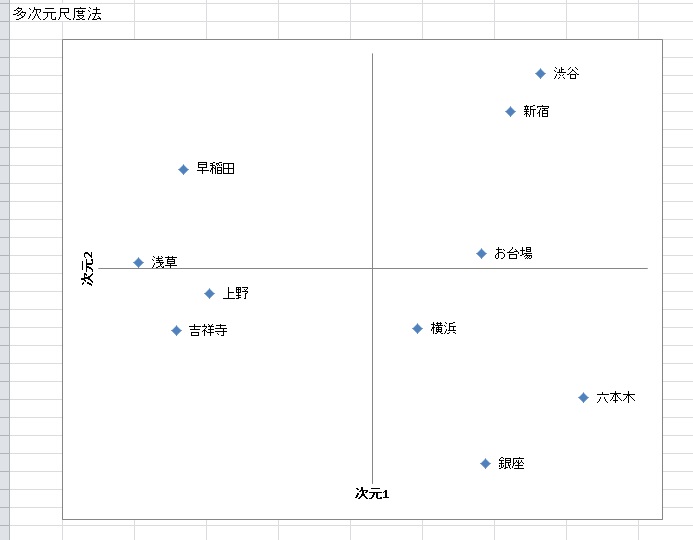
多次元尺度法でも、大きく分けて2つのグループがあることがわかります。