HAD9.3から、コレスポンデンス分析ができるようになりました。
コレスポンデンス分析(対応分析といわれたりもします)は、名義尺度水準のデータを数量化し、量的に分析可能な得点を得る方法です。日本では、林の数量化理論Ⅲ類と呼ばれるものが有名ですが、それと数理的には同じモデルです。
正確に言うと、コレスポンデンス分析はクロス表を数量化し、各カテゴリをマッピングする方法で、2つの名義尺度変数の関連を見る方法でした。しかしその後、多重コレスポンデンス分析というのが登場し、2変数以上でも関連が見られるようになりました。数量化Ⅲ類と同じなのは後者の多重コレスポンデンス分析です。この記事では面倒なので、コレスポンデンス分析で統一します。
HADでは、3種類のデータセットからコレスポンデンス分析を実行できます。それは、
- 変数型
- カテゴリー反応型
- クロス表
です。
1.は、名義尺度水準の変数を指定して分析します。例えば3つのカテゴリーをそれぞれ1、2、3とコードしたような変数を使う場合です。
2.は、各カテゴリーに対して当てはまる(反応する)場合に1、そうでない場合に0とコードしたようなデータを使う場合です。名義尺度の水準がすべて2の場合は、1ではなく2の方法を使う方が結果が見やすいでしょう。
3.は、2変数のクロス表のデータです。「はい・いいえ」と「男性・女性」のそれぞれの人数を表現したデータが当てはまります。
それでは、実際にHADでコレスポンデンス分析を実行する方法を見ていきましょう。
興味ある人は続きを見てください。
HADの基本的な使い方については、こちらの記事を見てください。
◆クロス表を使った分析
それでは、まずはクロス表を使った方法です。
以下のようなデータを使います。これは藤井・小杉・李(2005)の『福祉・心理・看護のテキストマイニング入門』の4章で使われているデータです。
ラーメン店6つを何人かの参加者に試食してもらい、コメントの中に含まれているキーワードの出現頻度を表にしたものです(架空のデータです)。
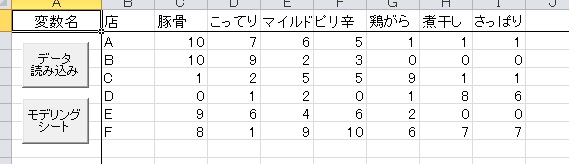
クロス表を入力するときは、ID変数として行カテゴリの名前を、変数名として列カテゴリの名前を入力します。入力したら、「データ読み込み」ボタンを押します。するとモデリングシートに移動するので、「使用変数」のところに列カテゴリの名前をすべて投入します。「変数をすべて投入」ボタンを押すと便利です。
次に、「因子分析」ボタンを押すと「因子分析」用のモデリングスペースが表示されます。そのスペースにある「対応分析」ボタンを押すと、以下のようなモデリングスペースが表示されます。

ここでは「データ」のところで「クロス表型」を選択します。それ以外はそのままでOKです。
あとは「分析実行」を押せば、コレスポンデンス分析が実行できます。
分析結果は「MCA」という名前のシートに出力されます。
相関係数は、各次元ごとの行と列の関連の強さを表しています。大きいほど、その次元でクロス表を強く説明できていることを示しています。
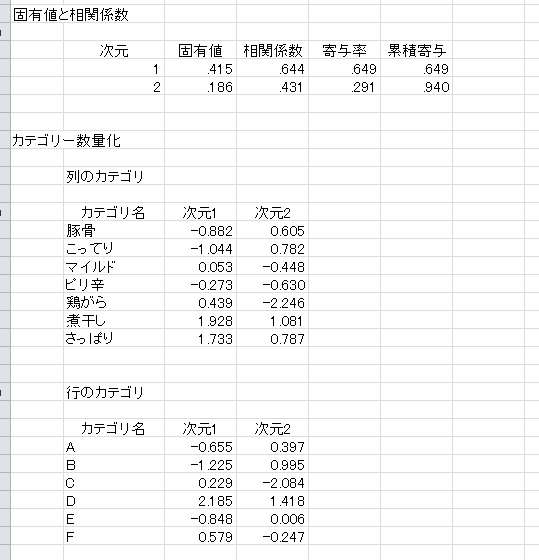
次に、列・行それぞれのカテゴリ数量化をもとに、2次元上にマッピングします。
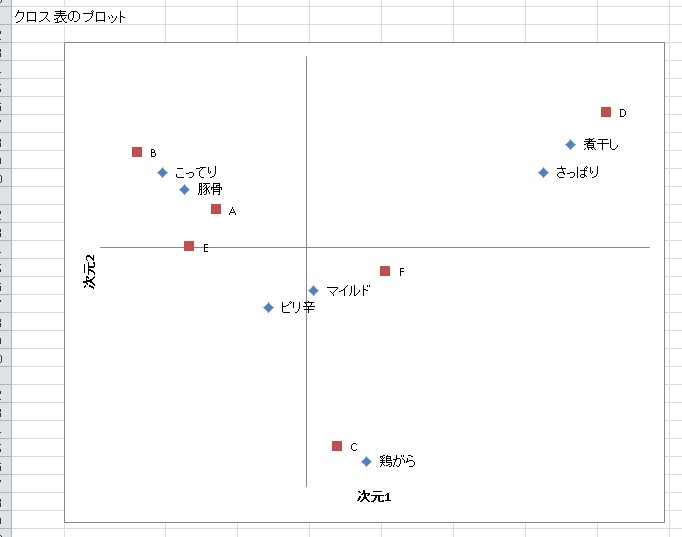
マッピングの結果を見ると、A店とB点とE店はこってり系の豚骨ラーメンの店であることがわかります。
◆変数型データを使った分析
さっきは2変量(味の表現と店)のクロス表を分析しましたが、変数型データセットを用いれば複数の変数間の関係を見ることができます。
例えば、次のようなデータを得たとします。
このデータは、各店ごとに「こってり」や「マイルド」といった、味の評価を3段階で評定してもらったデータです(架空のデータです)。
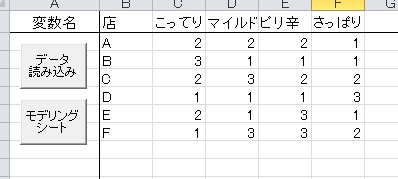
このデータも同じように読み込み、コレスポンデンス分析のスペースで今度は「変数型」を選びます。そして、分析実行を押せば、以下のような結果が得られます。
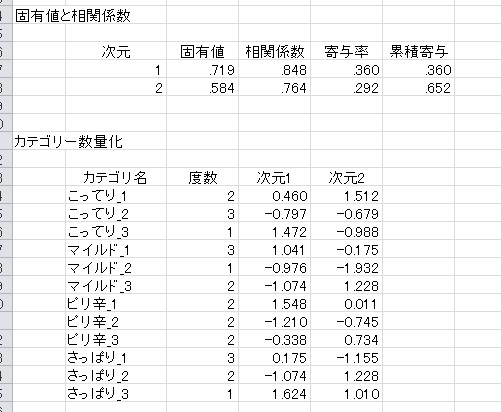
各変数ごとに、1~3のカテゴリがそれぞれ数量化されます。この結果をマッピングすると、以下のような結果を得ます。
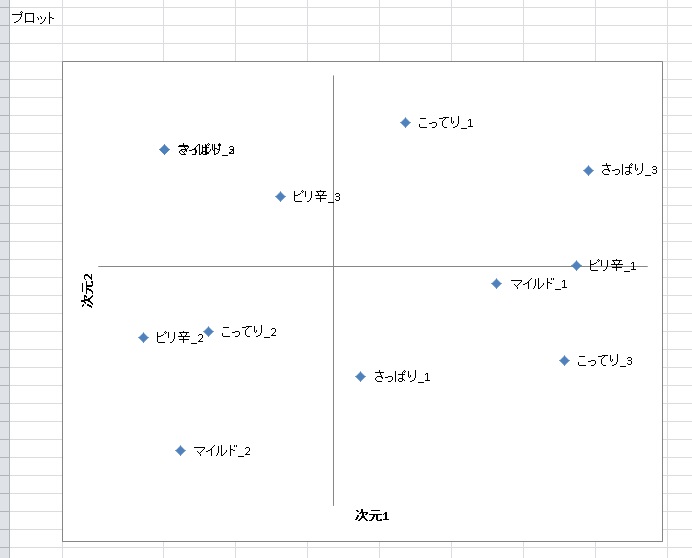
このように、変数型を使えば複数の変数の関連を検討することができます。
◆カテゴリ反応型データを使った分析
カテゴリ反応型データとは、カテゴリに反応したら1、そうでなかったら0となるようなデータセットのことをさします。先ほどのデータをカテゴリ反応型に変換すると、以下のようになります。
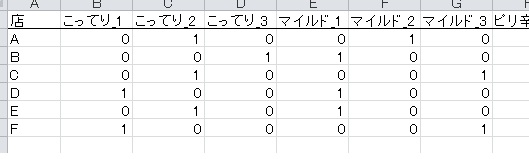
A点の場合、こってりは2と評価されているので、こってり1やこってり3は0、こってり2が1になります。つまり、データはすべて0か1になるようなデータセットのことです。
HADではこのタイプでも同様に分析ができます。結果の出力は変数型と同じです。
◆その他のオプション
・重み
重みとは、カテゴリのスコアを次元の固有値(の平方根)で重みづけるかどうかを意味しています。デフォルトは重みを付けていません。
・得点
- 回答者のスコア:変数型やカテゴリ反応型データセットは、行は回答者を意味しています。その場合、各回答者の次元ごとのスコアを出力することができます。このスコアを使えば、その後クラスター分析などに使用できます。
- カテゴリ反応型データ:変数型データセットの場合、それをカテゴリー反応型に変換します。いわば、カテゴリカルデータをダミー化する作業です。
・出力
プロットするときに、回答者データと変数データを表示するかどうかを選択します。両方も可能です。
以上が、HADでコレスポンデンス分析をする方法でした。